El desarrollo de las tecnologías del lenguaje para el futuro de la sanidad
La transformación digital muestra la importancia de las tecnologías en el devenir socioeconómico del país. Llevamos años escuchando que los datos son el petróleo del siglo XXI. Sin embargo, almacenar datos no permite aumentar la competitividad de sectores esenciales como la sanidad si no se aplican nuevas técnicas para extraer información de ellos.
Esto se puso de manifiesto el pasado 13 de abril del 2021 cuando el Gobierno de España presentó el Plan de Recuperación, Tranformación y Resiliencia. Este documento perfila las inversiones que se realizarán en los próximos 10 años para la recuperación económica del país tras la pandemia.
Dentro del plan se hace hincapié en la renovación del sistema público de salud mediante la innovación tecnológica y métodos disruptivos que mejoren el tratamiento de los datos. También destaca la importancia de desarrollar una Estrategia Nacional de Inteligencia Artificial (IA) que nos permita ser líderes en el desarrollo de estas tecnologías en español, entre las que están las tecnologías del lenguaje.
El área que une la inteligencia artificial, las tecnologías del lenguaje y el sector salud se conoce como “procesamiento del lenguaje natural clínico”, generalmente nombrada por sus siglas en inglés “NLP Clínico”.
La importancia de las tecnologías del lenguaje en el sector de la sanidad
En su día a día, los médicos describen el estado de sus pacientes en forma de notas clínicas que se guardan en bases de datos de hospitales. Esta información almacenada en forma de texto representa el 80 % de los datos de salud de los pacientes.
El texto, a diferencia del contenido numérico, no puede introducirse de forma directa en los sistemas de apoyo al diagnóstico que ayudan a los profesionales a realizar su trabajo más eficientemente. Tratar este tipo de contenido de manera manual requeriría una gran cantidad de horas de trabajo solo para poder leer cada informe. Las tecnologías del lenguaje ayudan a ampliar el volumen de datos sobre los pacientes de manera automática, para lo cual extraen la información de sus historiales clínicos y proporcionan más datos a los médicos.
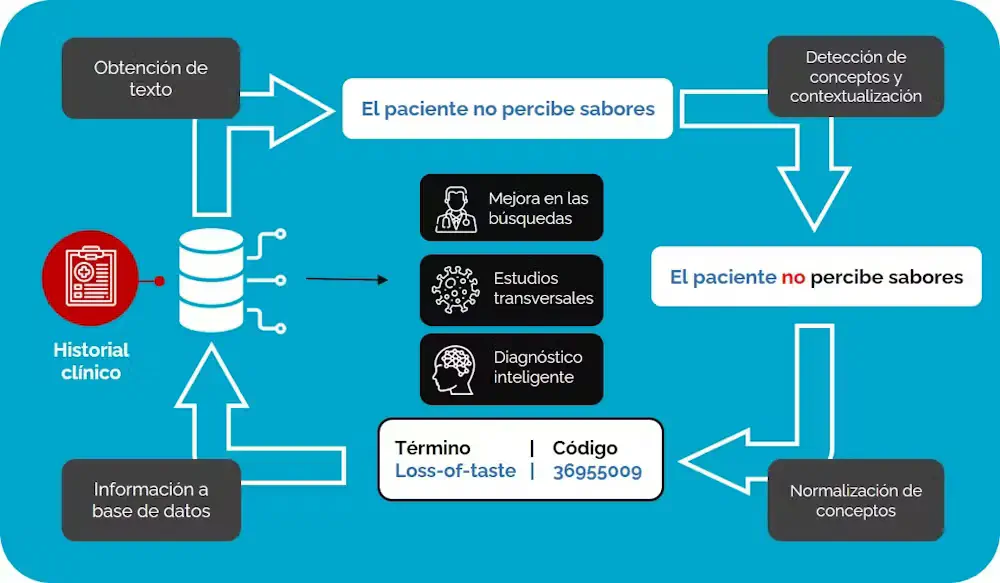
El NLP clínico actual se sostiene en tecnologías de inteligencia artificial. Partiendo de una historia clínica, el sistema detecta en primer lugar conceptos médicos que permiten caracterizar a pacientes y subgrupos poblacionales. La IA puede detectar menciones a medicamentos, síntomas, enfermedades, patógenos y procedimiento, entre otras cosas.
A continuación, analiza el entorno de estos conceptos para contextualizarlos y comprender su significado. Por ejemplo, el término “percibe sabores” tendrá diferente significado en función de la presencia de partículas de negación previas al concepto.
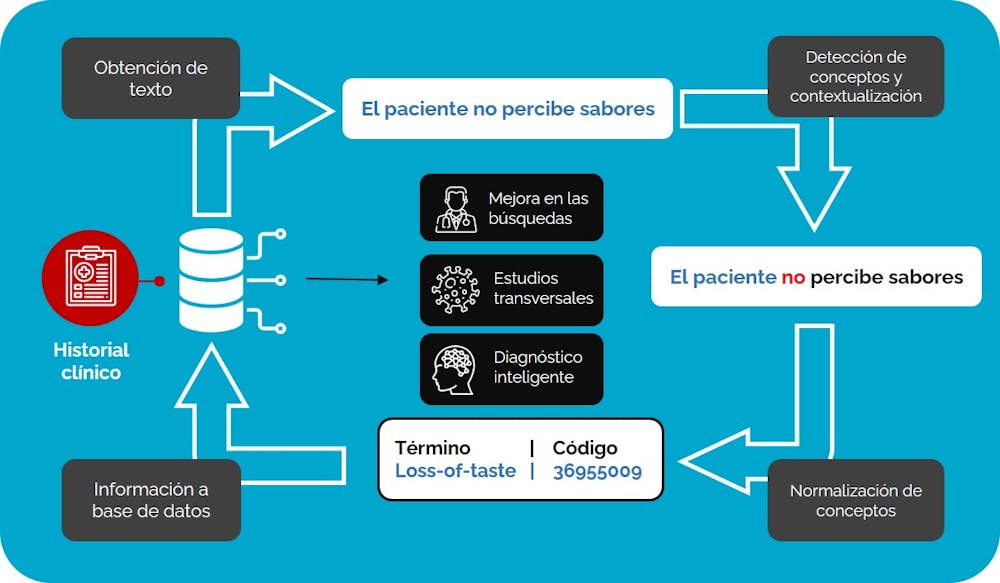
Por último, el sistema asocia los conceptos con categorías médicas normalizadas procedentes de terminologías jerárquicas clínicas como SNOMED-CT. Esto permite representar de forma normalizada el contenido del texto y que la información pueda intercambiarse entre todos los sistemas tecnológicos del hospital e incluso con otros sistemas clínicos a nivel nacional e internacional.
Una vez extraída la información contenida en las historias clínicas es posible incorporarla con el resto de herramientas de informática médica del hospital y desarrollar nuevas funcionalidades. Entre otros, podrían implementarse sistemas que identifiquen pacientes similares a partir del contenido de sus historias clínicas o ampliar el conocimiento sobre enfermedades a través de búsquedas sencillas en bases de datos.
Por ejemplo, podrían realizarse estudios transversales sobre presencia de síntomas en enfermos de covid-19 en función de sus antecedentes médicos o edad.
Además, la pandemia ha mostrado la necesidad de acceder a información relevante de forma rápida para tomar decisiones. Gracias a las tecnologías del lenguaje se podría centralizar la búsqueda y mejorar la contextualización de la información médica. A partir del análisis semántico de los textos podrían recuperarse información de historias clínicas, artículos científicos o ensayos clínicos que permitieran tratar una enfermedad con todas las evidencias científicas disponibles.
Desarrollo del NLP Clínico en español
El inglés es el idioma de la ciencia, y gran parte de las tecnologías del lenguaje se desarrollan en la lengua de Shakespeare. Sin embargo, la importancia de otras lenguas como el español en el campo médico es innegable. Más de 500 000 profesionales de la salud utilizan este idioma de forma diaria. Es necesario generar recursos en este idioma si queremos beneficiarnos de estos avances.
Uno de los cuellos de botella en el desarrollo de sistemas de NLP Clínico en español es el acceso a los datos, esenciales para entrenar sistemas de IA. Los datos clínicos son de carácter muy sensible y el acceso a ellos está muy restringido incluso a investigadores públicos. La protección de los derechos fundamentales de los ciudadanos están garantizados gracias a leyes de protección de datos como la LOPD.
Debido a las dificultades de acceso a datos reales, se han popularizado las campañas de evaluación de sistemas de NLP. Estas actividades son una de las principales líneas de avance en el NLP Clínico. Tienen carácter competitivo: sistemas procedentes de equipos de universidades e industria se enfrentan para conseguir el mejor rendimiento en una tarea concreta. Para ello, los organizadores preparan un conjunto de datos reales ya publicados, los anotan de forma consistente siguiendo guías de anotación, y, finalmente, los distribuyen entre los participantes, que los utilizarán para entrenar modelos predictivos que serán evaluados frente a un sistema de referencia.
El carácter competitivo de estas campañas favorecen la rápida evolución del NLP clínico en español. Programas como el Plan de Impulso de las Tecnologías del Lenguaje dotan de recursos a los centros de investigación españoles para organizar competiciones de alto impacto. Un ejemplo es PharmaCoNER, para reconocer y normalizar menciones a fármacos. También CODIESP, para codificar menciones a procedimientos médicos y síntomas de historias clínicas con terminologías controladas.
El conjunto de todas las tareas cofinanciadas ya aglutina más de 80 equipos participantes provenientes de instituciones de investigación de gran importancia. La participación de empresas resalta el interés que suscita el desarrollo de sistemas de NLP Clínico en español para la industria.
NLP clínico y seguridad de datos
En los últimos tiempos nos hemos acostumbrado a descubrir escándalos relativos al uso fraudulento de datos personales como el de Cambridge Analytica. Estos casos no deben empañar las posibles aplicaciones positivas de la IA en nuestras vidas.
Las instituciones europeas siempre han mostrado una especial atención a la protección de los datos personales para evitar que se atente contra los derechos de los ciudadanos comunitarios. Primero se aprobó la Ley General de Protección de Datos, de obligado cumplimiento en todo Europa. Actualmente se están poniendo en marcha nuevos protocolos que permitan incrementar el nivel de seguridad de los datos médicos para evitar su uso fraudulento.
La protección de datos médicos está garantizada por los órganos competentes en la materia, y especialmente la de carácter sensible. Los investigadores solo tienen acceso a datos anonimizados, ya que su único fin es generar recursos y sistemas que permitan aumentar la eficiencia del sistema público de salud, así como la calidad y rapidez en el diagnóstico.
Actualmente, los autores del artículo están buscando participantes para una nueva edición de las campañas de evaluación MESINESP2 y MEDDOPROF, organizadas junto a instituciones de prestigio como la Organización Panamericana de la Salud y el Instituto de Salud Carlos III, con las que se busca seguir generando recursos del lenguaje en español para mejorar la eficiencia del sistema de salud estatal.![]()
Luis Gascó, Text Mining Research Engineer (RE2), Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS); Antonio Miranda-Escalada, NLP Research Engineer, Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS); Eulalia Farre, Paediatrician working in biomedical text mining and natural language processing, Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS); Martin Krallinger, Researcher Life Sciences - Text Mining, Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS) y Salvador Lima López, Lingüista Computacional, Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS)
Este artículo fue publicado originalmente en The Conversation. Lea el original.